



Dynamo is a key-value store developed by Amazon with the main focus on availability. Amazon was relying on the Oracle database, but they fastly reached its upper scaling limits. So they decided to build an in-house database to handle the massive scale they are operating at. In this article, I will provide a summary of Dynamo design paper.
Let's start by visiting the design goals for the system, which will, later on, help in understanding the chosen architecture, algorithms, and also the trade-offs taken while designing Dynamo.
Design goals:
Incremental scalability: the system should be easily expandable by adding more computation power (ex: extra nodes) to handle any increase in the system loads.
Symmetry: All nodes are peers (no special nodes).
Decentralization: To avoid single point of failure.
Availability: It represents the ratio between the system uptime to the total time over a given period. From the CAP theorem you can only achieve two goals out of Consistency, Availability, and Partition Tolerance. Dynamo is an AP system where consistency takes a hit to be available and partition tolerant.
Eventually Consistent: As mentioned in the previous point, Dynamo is designed to be eventually consistent, this means writes are considered successful before its propagated to all nodes.
After we discussed the design goals of the system we can have a look at the system interface which will help in having a high-level understanding of what is the system's main functionality.
System Interface
get(key): Returns an object associated with the key, or list of objects with conflicting versions alongside with the context which represents encoded metadata related to the object.
put(key, context, object): First, determine which nodes should store the object based on the key value. Secondly, it stores the object in the decided nodes alongside its context.
Architecture Overview
Partitioning Algorithm: To address the problem of how the data is distributed across the nodes, consistent Hashing is used where data keys and nodes are hashed to the same space. Also, virtual nodes are used to avoid un-even distribution in case of failure or adding new nodes.
Replication: Each data is replicated to N different physical nodes where N is a configurable parameter. The first node in the hash ring for a given key is called the coordinator node which first stores the data then replicates the data to N-1 other nodes. Each node in the system can decide the N physical nodes where we should store the data of any given key.
Hinted Handoff: If one of the replicas is down, the next physical node is used to store the replicated data temporarily with a hint about the intended node, and once the failure is recovered the replicated data is sent to the intended node.
- Data Versioning: Versioning in distributed systems is very challenging, if we are in a single machine we can easily rely on a counter or the local machine time to reconcile different versions of the data. However, in a distributed system due to clock skew, this can not hold any more. There are different synchronization algorithms, the one used in Dynamo called vector clock where we store a list of pairs of node ID and node time for each new version of the data. This data used to reconcile the latest version of the data. The below figure represent four writes on the same key first two happen when the system was healthy, then a partition happened to the system so that D3 and D4 each node has a different version of the data, and It's impossible to reconcile using only vector clock. What happens, in this case, is that Dynamo returns to the client all versions and let the client do semantic reconcile and store back the reconciled data.
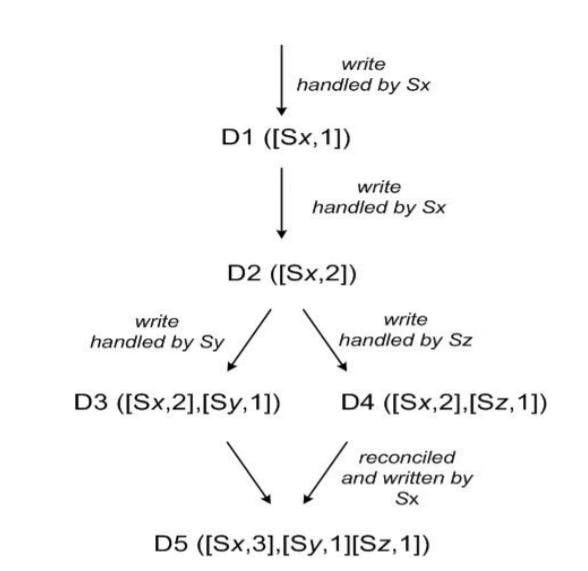
Dynamo (also Cassandra) offers another reconciliation policy called last write wins where we consider the most recent write using wall-clock timestamp. It's a simpler automatic way to resolve conflicts but may also result in data loss.
Execution of get () and put () operations: There are two ways offered to the client to talk to the Dynamo cluster, first by forwarding the request to a load balancer which is responsible for maintaining the current state of the cluster and forwarding the request to the appropriate node. In this way, it provides a loosely coupled architecture but an extra communication step over each request. The second way it helps in providing low latency, in this case, clients are maintaining a copy of the nodes in the cluster, and it sends the requests directly to the nodes. Get operation is executed by sending a request to the coordinator which requests the data from top N-1 healthy nodes and then wait till at least R-1 replicas reply and then reconcile the data in case of conflicts and return the results to the client.
Ring Membership: Dynamo cluster uses a gossip protocol to maintain the state of the cluster in each node. In gossip protocol, each node sends all the information about all the nodes to each other nodes it's aware of. Eventually, each node will know about each other node, however there is a probability of ending up with logical partitions.
This article discussed a summary of Dynamo architecture with details on each main component. Next, I would recommend giving a read to the design paper, And if you have any questions or parts that need to be cleared feel free to reach me in the comments.
See you in the next article ;).