

The Facebook Journey to Reduce Social Graph Storage By Half (MyRocks)


TL;DR : In this article, we will go through the motivation why Facebook decided to change the InnoDB storage engine and replace it with MyRocks. Also, we explore how they designed MyRocks what are the challenges, how they planned for the migration, and finally what are the lesson learned.
Recently, while reading a technical blog post about different MYSQL storage engines I heard for the first time about MyRocks, a storage engine developed by Facebook. I decided to learn more about it. Luckily I found their design paper "MyRocks: log structured merge (LSM) tree Database Storage Engine Serving Facebook's Social Graph" published on Facebook publications website . In this article, I am going to cover MyRocks in more detail while highlighting the motivation, design goals, challenges, impact, and how they managed the migration at this scale.
Facebook's User Database (UDB) is the main database that serves tens of petabytes of social activities. They are using MySQL to store the UDB. InnoDB is the default storage engine for MySQL which is a B+ tree based storage engine. There were two motivations behind looking into a new way to store the data, first minimizing the space, second having better write amplification. InnoDB was not the ideal choice for those two problems due to index fragmentation, compression inefficiencies, and space overhead per row (13 bytes) for handling transactions.
Write amplification is the ratio of the amount of data written to the storage device versus the amount of data written to the database.
B+ tree vs LSM-Tree Closer Look
I would like to zoom more on the B+ tree vs LSM-Tree and see what is the difference between both data structures and how we can benefit from each one, based on our use case. First, B+ tree is a self-balancing tree data structure that maintains sorted data and allows searches, sequential access, insertions, and deletions in logarithmic time. The figure below shows an example of a simple B+ tree.
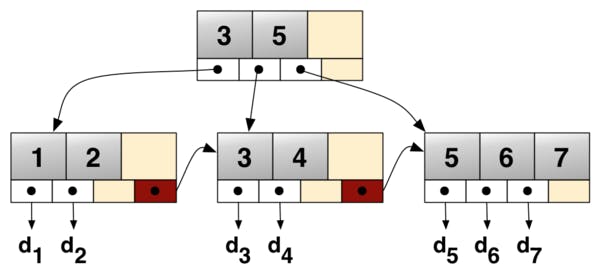
However, if we optimize for heavy write operations we can do better in the insertion operation, here where LSM-Tree has an advantage, LSM stands for log-structured merge. LSM-Tree uses a write-ahead log (WAL) where it appends the new writes to it. While this gives O(1) time complexity per write operation it increases the search operations to O(N) as data is not sorted anymore. LSM relies on a hybrid solution to make writes efficient while not affecting search operations. The main idea is to maintain multiple levels for the data, the first level is in memory where writes are stored and then moved sorted to the disk once its size hits a specific threshold. Now we will end up having many sorted tables in the disk we need to search while executing the read operation. Two optimizations are used to overcome this problem: first compaction which is the process of merging the small tables into large enough tables ( this operation has to balance between having too big tables or too many tables), The second optimization by using bloom filters. The below figure is a good visualization for a two-level LSM-Tree where it also visualizes the compaction operation.
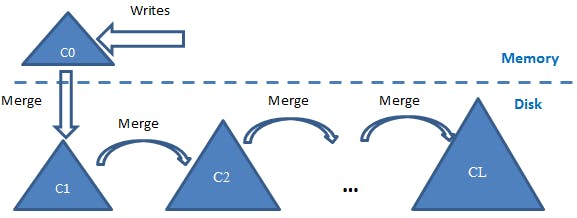
LSM-Tree based databases already exist, for example RocksDB which was also developed by Facebook. However, the challenge here is that there are already too many clients using UDB, and rewriting all the clients will take much time, so to avoid that they decided to wrap RocksDB in a storage engine (MyRocks) and integrate it with MySQL. The figure below gives an overview of the architecture.
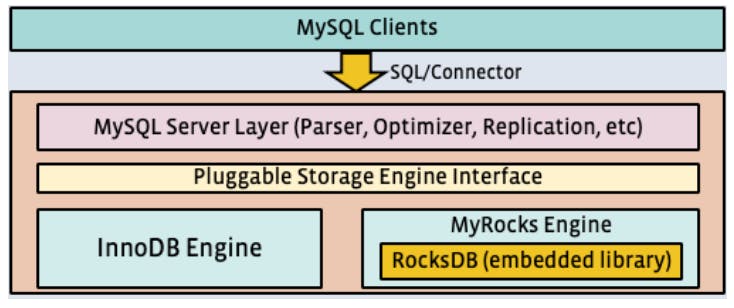
Design Goals
Maintained Existing Behavior of Apps and Ops: As mentioned earlier, given the number of clients and tools already using Mysql client and to avoid migrating them all it was necessary to maintain the existing behavior and hence the choice of integrating RockDB as a pluggable storage engine.
Limited Initial Target Scope: Only scope the design for UDB use case and its table structure and query pattern to reach fast to production-ready database.
Set Clear Performance and Efficiency Goals: The main goal is to reduce the space by at least 50% while making sure that there is no regression on CPU and I/O usage. Please note here those goals are achievable for the UDB use case while LSM-Tree is better in write operations, it increases the CPU usage for the read operations. So in different situations, InnoDB will perform better than MyRocks even in terms of CPU usage.
If the space is reduced by 50% so each server will serve double the load so it will be a challenge to avoid regressions in CPU and I/O.
Design Choices
Contributions to RocksDB: As much as possible features are added to RocksDB to benefit other applications that are also using RocksDB APIs.
Clustered Index Format : MyRocks adapted the same InnoDB cluster index structure. So primary key lookups could be done by single read as all columns are present. While secondary key entries include primary key columns to reference the actual entries.

In the following section, we will cover the performance challenges and how they overcome them.
Performance Challenges
In this section, we will focus on the main challenges in the road of building MyRocks and how they were able to overcome them.
- CPU Reduction
- Mem-comparable Keys : MyRocks doing more k key comparisons in lookups compared to InnoDB, especially for range queries where we have to only perform one binary search in B-Tree to find the start of the range while on LSM-Tree you will need to do before a binary search for each stored run.
- Reverse Key Comparator : Due to the way LSM-Tree is implemented it supports better forward iterations while it consumes more reading cycles while doing backward iterations, to overcome this they implemented a reverse key comparator where they store the keys in reverse order so in the end, it's internally doing forward iterations while executing reverse scans. This improved descending scan throughput by approximately 15% in UDB.
- Faster Approximate Size to Scan Calculation : MyRocks needs to tell the MySQL optimizer the estimated cost to scan for each query plan candidate. To implement this they used two approaches first one skipping cost calculation when a hint to force a specific index was given, this was based on the UDB use case as for some specific queries they can force the query execution plan that optimized most for such query.
- Latency Reduction/Range Query Performance :
- Prefix Bloom Filter : UDB contains many range queries, In B-Tree you can reach to start leaf in logarithmic time. However, in LSM-Tree you need to scan multiple sorted runs. As a solution for this, they introduced a prefix bloom filter where it can fastly tell if the sorted run may contain any key starting with a given query or for sure it does not contain any key with such prefix.
Bloom filter: Are a probabilistic data structure that can tell you fastly whether an element is presented in a set or not.
- Reducing Tombstone on Deletes and Updates : As we mentioned early UDB uses composite keys to minimize the random read for primary keys while this improves the read performance in LSM-Tree it means any updates to the indexed columns require an update to the key. Frequent updates in LSM-Tree results in some deleted entries remains existing in deeper levels (Tombstone), more of Tombstones we have the slower the range query as the bloom filter will match many sorted runs then after we scan them we figure out its Tombstones. To avoid this they introduced SingleDelete because it is easier to delete a key when we know for sure there is at most one version of it. The MyRocks secondary key prevents multiple Puts to the same key if a secondary key is updated a SingleDelete is executed first.
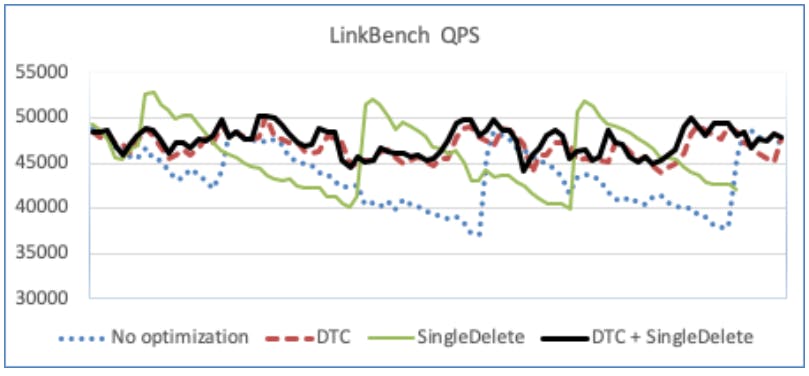
- Triggering Compaction based on Tombstones : When deleting a large number of rows some SST files might end up with too many tombstones, to avoid this they introduced Deletion Triggered Compaction (DTC). While doing flush or compaction if a high-density key range is deleted, it issues another compaction to minimize the tombstones in SST files. The below figure compares the QPS overtime with no optimization, DTC, SingleDelete, and DTC+SingleDelete.
- Space and Compaction Challenges
- DRAM Usage Regression: As mentioned in the previous section bloom filter was needed to optimize MyRocks for range queries and minimize empty SST lockups. However, this results in regression in memory usage comparing to InnoDB. To overcome this MyRocks was configured to optionally skip creating bloom filter on the last level where 90% of the data reside, while bloom filter still effective this option will optimize the memory of the bloom filter by 90% while increasing the CPU per query because of the empty lookups in the last level.
- SSD Slowness Because of Compaction:Compaction is very intensive operations which creates hundreds of megabytes to gigabytes of SST files, it can easily compete on I/O with users queries, to resolve this they introduced rate limit to file deletion during compaction.
- Physically Removing Stale Data: The typical social graph work load by adding new entries with increasing primary key ID. Old IDs have a lower probability to be modified hence their SST has a lower probability to be picked up for compaction. This issue causes some deletion to never make their way to the Lmax. They introduced periodic compaction which triggers compaction on SSTs in case it contains data older than a specific threshold.
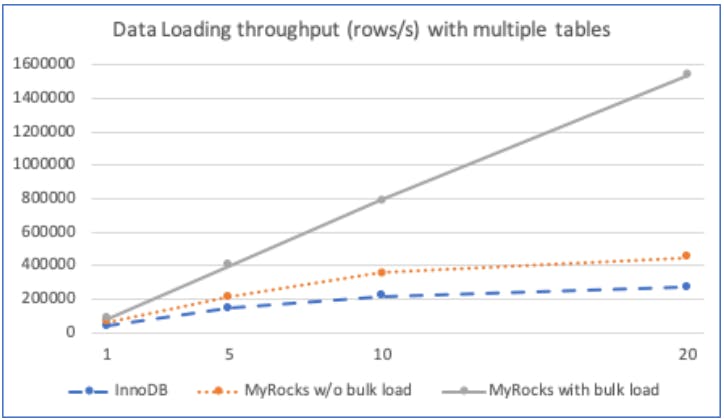
- Bulk Loading: One of the main sources of the cause stall in LSM-tree databases is massive data write for example migrating the data from InnoDB to MyRocks, such operation will stall the users' query. They mitigated this problem by implementing bulk loading which allows writing SST directly to Lmax skipping MemTable and compaction. The below figure shows the performance impact with/out bulk load and compares it to InnoDB.
So far I covered MyRocks data storage and its design goals, challenges and how they are addressed. In the next section I am going to cover how they did such a large scale migration.
PRODUCTION MIGRATION
MyShadow – Shadow Query Testing: Before enabling MyRocks in production it's needed to be extensively tested on production queries, So they used MyShadow which is an in-house MySQL plugin that captures the production queries and replays them to MyRocks replica which allows them to capture data inconsistency or query regressions.
Data Correctness Checks: To check the data correctness they developed internal validation tools with different checks modes Single, Pair, and Select. The three modes vary between checking the consistency between overlapped columns, checking against other instances, and verifying data consistency for select statements captured by MYShadow.
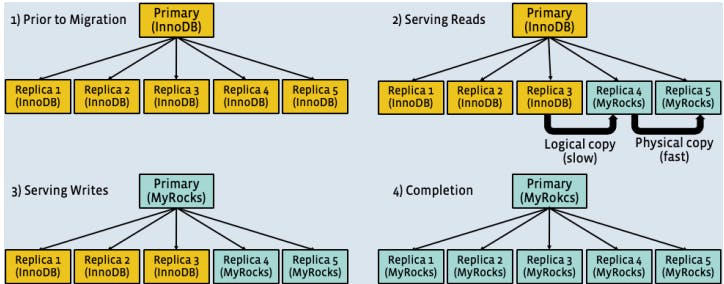
Actual Migration : Actual migration happens through three main staging, First serving reads only and making sure MyRocks can reliably serve production queries by only having two MyRocks replicas out of five replicas. Secondly promoting MyRocks to master and serving writing queries. Finally migrate all instances to MyRocks. During all stages a backup InnoDB replica set was mantained for any need of rollbacks. Below figure summarize all migration steps.
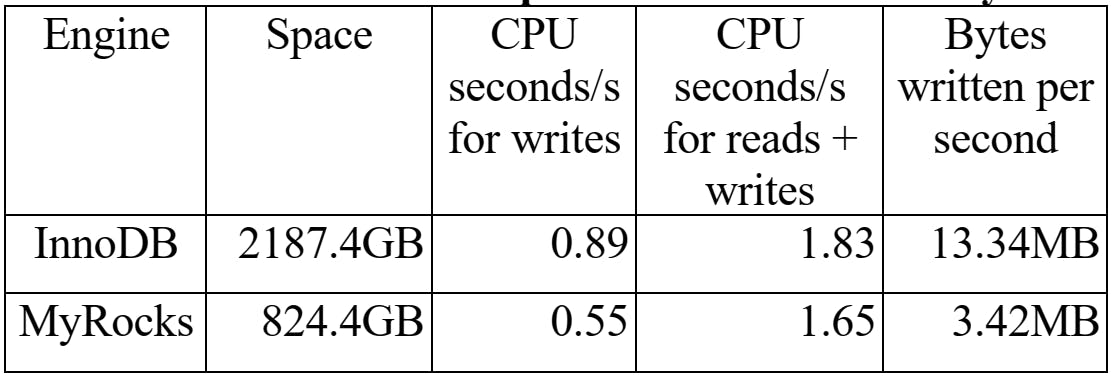
I woud like to go over a summary of UDB statistics comparision between InnoDB and MyRocks. MyRocks instance size was 37.7% compared to the InnoDB instance size with the same data sets. On the other hand it shows 40% improvment for CPU usage while serving write traffic, while CPU efficiency on both read and write queries are slightly less on Rocks DB. the below table summarizes the comparision numbers between InnoDB and MyRocks.
Finally, I would like to summarize the main lessons learned by them during this challenging engineering solution.
Main Lessons Learned:
- understand how core components worked, including flash storage and the Linux Kernel, from development to debugging production issues.
- Do not ignore outliers, many of the production issues they faced can not be detected by checking only p90 or p99 so monitoring should be able to detect very rare data points.
- SQL compatibility of MyRocks helped them to make use of all internal tools and plugins they already developed.
- LSM-tree has many parameters that need to be tuned based on the application, as a long goal for them is to make it less complicated to make use of it in different workloads.
In this article I covered the main points and sections in MyRocks: LSM-Tree Database Storage Engine Serving Facebook's Social Graph paper, there is much more you can learn and check in the paper itself. If you have any questions feel free to reach out throughout the comments. See you in the next article.